Write Better Specs, Ship Better Code
66% of developers spend more time fixing AI-generated code than they save. The problem isn't model capability - it's vague specifications. Here's how Spec-Driven Development turns user stories into the new source code.

- 01
- 02
- 03Write Better Specs, Ship Better Codereading now
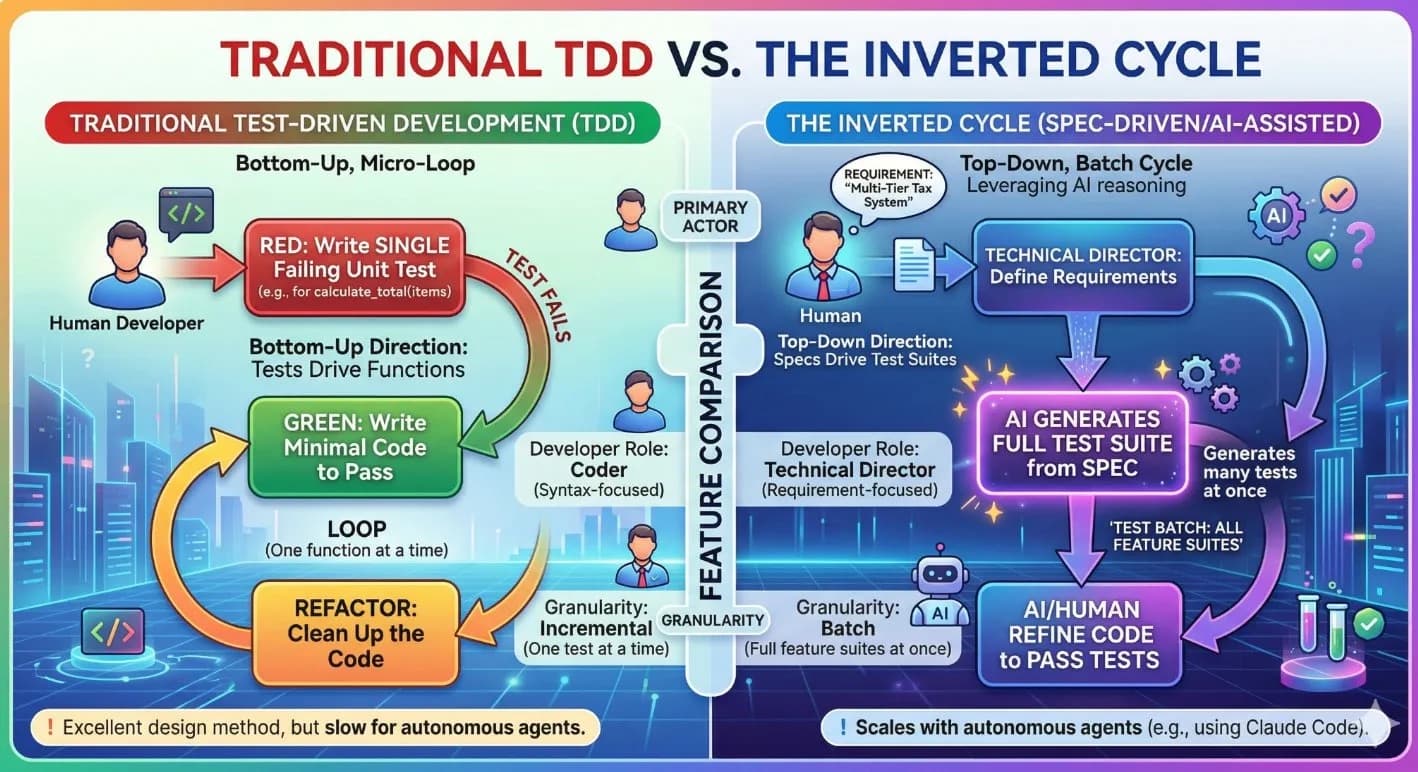
Earlier in this series, we covered how the Inverted TDD Cycle and MCP tools provide the guardrails and the hands for AI-assisted engineering. Together they form the execution layer - the workflow that keeps agents accountable and the tooling that lets them act.
But even with the best workflow and the most powerful tooling, most enterprise teams eventually hit the same wall: their agents produce almost-right code that passes the tests it was given yet somehow doesn't reflect what stakeholders actually asked for. The scenarios were green. The implementation was wrong.
According to the 2025 Stack Overflow Developer Survey, 66% of developers report spending more time fixing AI-generated code than they save by generating it. The culprit isn't model capability. It's what you're feeding into the model.
At Kipanga, we found our specification documents had to evolve. The user stories that worked in traditional Agile are too abstract for AI agents to handle reliably. To close the gap, we now treat our specifications the same way we treat source code - versioned, reviewed, and authoritative.
Specifications are the new source code. The quality of what your agents produce is bounded by the quality of the constraints you give them.
The Problem with "Vibe-Only" Requirements
Most engineering teams still hand their AI agents a user story like this:
As a user, I want to reset my password.When a human engineer reads that, their brain fills in the context automatically - hashing algorithms, salt rotation, token expiration windows, and rate limiting. Years of pattern-matching against production incidents turn one sentence into a full mental specification.
An AI agent has no such pattern library. It is, fundamentally, a confident guesser. If you don't state a constraint explicitly, the agent will invent one - and it almost always invents the happy-path implementation that crumbles at the first security audit.
GIST Debt: The Cost of Unstated Assumptions
We call this GIST Debt - technical debt that accumulates not from laziness, but from the uncertainty of AI-generated assumptions. Traditional technical debt is a conscious trade-off; GIST Debt is invisible until an auditor, a penetration tester, or a production incident makes it visible.

This is why teams that adopt AI coding without evolving their specs see an initial velocity spike followed by a debt tsunami. The code ships faster, but the assumptions baked into it are opaque, undocumented, and frequently wrong. You haven't sped up delivery - you've just shifted the cost from writing to reviewing, investigating, and rewriting.
Moving to Spec-Driven Development
To scale vibe coding in a professional setting, we've moved from prompting to Specification-Driven Development (SDD). In SDD, natural-language instructions aren't throwaway wishes - they're authoritative, version-controlled blueprints that live alongside the code they produce. Specs go through pull requests. Specs get reviewed. Specs are the contract.
The ROI on this shift is striking. In one gaming-industry case study, moving from vague user stories to structured specs increased flow efficiency from 32% to 85%. The time spent on active engineering work didn't change; what collapsed was the alignment overhead - the endless back-and-forth between humans and agents trying to clarify intent.
That alignment overhead is exactly where GIST Debt accrues. A well-structured spec doesn't just tell the agent what to build; it eliminates the clarification conversation that used to be required to figure out what "done" actually means. This shift (from prompting to Spec-Driven Development) is the single highest-leverage change we teach at our AI Augmented Academy.
Requirements That Work for Agents
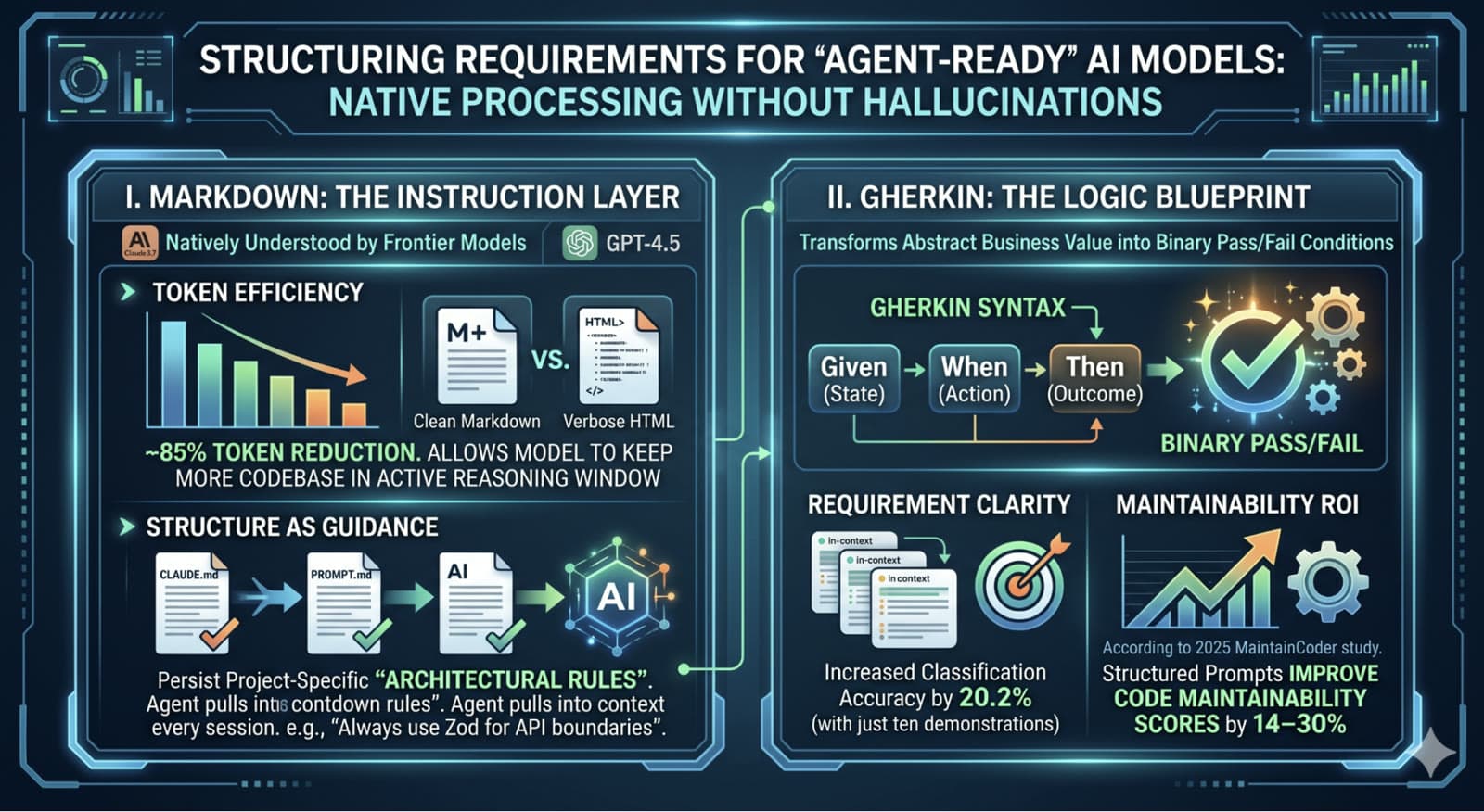
For a requirement to be agent-ready, it needs to be structured in a way that frontier models can process natively - without filling in gaps through confident guessing. Two formats do most of the work.
Markdown: The Instruction Layer
Markdown stopped being a documentation format years ago. For AI agents, it is the instruction layer - the native interface through which you configure model behavior. Frontier models like Claude 3.7 and GPT-4.5 parse Markdown structure as semantic hierarchy, not decoration. Headings are sections. Lists are constraints. Tables are schemas.
Two properties make it uniquely well-suited to agent instructions:
- Token efficiency. Serving requirements in clean Markdown instead of HTML or verbose prose reduces token consumption by roughly 85%, which means the model can keep more of your actual codebase in its active reasoning window and make better architectural decisions.
- Persistent architectural rules. Purpose-built Markdown files like
CLAUDE.mdorPROMPT.mdlet you persist project-specific rules the agent pulls into every session - for example, "Always use Zod for API boundaries" or "Database calls must go through the repository layer." These act as durable context across turns, across agents, and across team members.
Gherkin: The Logic Blueprint
If Markdown provides the structure, Gherkin provides the logic. The Given-When-Then syntax transforms abstract business value into binary pass/fail conditions - exactly the shape AI agents need to execute reliably.
Why Gherkin Works for Agents
Gherkin scenarios compile directly into failing tests. That means the agent's goal is no longer "understand what the user wants" - open-ended and drift-prone - it becomes "turn these specific scenarios green." The ambiguity collapses at the specification stage instead of leaking into production code.
The research backs this up across multiple dimensions:
What's striking about these numbers is that none of them are about model quality. They're about the interface between humans and agents. The model is the same; the input format is doing the work.
A Practical Example: Exporting to CSV
Abstract principles don't ship code. Let's look at a concrete requirement that shows up in almost every enterprise product: exporting a report to CSV.
In traditional Agile, this is often a one-sentence card on a Jira board. In an AI-assisted framework, that one sentence is a trap - it describes the goal and leaves every technical boundary to the model's imagination.
The Vibe Approach
Here's what most teams hand their AI agents:
As an Admin, I want to export our user list to a CSV file
so that I can analyze our growth in Excel.The agent's likely output: a button that queries the database and returns a raw text file. It will miss encoding requirements, column headers, permission checks, large-dataset handling, empty-state behavior, and any form of audit logging. Every one of those omissions is a place where GIST Debt accumulates - and where the 45% AI-security-vulnerability rate from the first post in this series comes from.
The Director Approach
Now here's the same requirement expressed as a high-fidelity Gherkin specification:
Feature: User Data Export to CSV
Overview: Provides a secure, performant way for Admins to download
user data for external analysis.
Constraints: UTF-8 encoding, Node.js stream-based processing for
large datasets, Zod schema validation.
Scenario: Successful export of active users
Given an authenticated user with the role "Admin"
And the system contains 5,000 active user records
When the Admin requests a "User Growth Report" in CSV format
Then a file named "user_growth_report.csv" is generated
And the file must download within 5 seconds
And the file content must use UTF-8 encoding
Scenario Outline: Validation of required columns
Given a successful export is triggered
Then the resulting CSV file must contain the header "<ColumnName>"
And the value for "<ColumnName>" must match the schema type "<DataType>"
Examples:
| ColumnName | DataType |
| Full Name | String |
| Email | Email_String |
| Signup Date | ISO_Date |
| Last Login | ISO_Date |
Scenario: Handling empty datasets (Edge Case)
Given the Admin filters the report to a date range with zero users
When the Admin attempts to export the data
Then the system returns a 204 No Content status
And an alert message "No users found for this range" is displayedSame feature. Fundamentally different artifact. Here is why the second version produces reliable code:
- Declarative precision. The spec describes the state the system must reach, not the sequence of clicks or API calls to get there. That gives the agent room to implement modularly and removes the ambiguity that produces logic errors.
- Explicit boundaries. The Scenario Outline forces the agent to implement column-level validation (Zod, Pydantic, or your stack's equivalent) for every field. There is no room for "the agent assumed strings were fine."
- Upfront threat modeling. The role constraint -
role "Admin"- is declared in the spec before a single line of code is written. Without it, an agent might happily expose the export endpoint to every authenticated user. That is a textbook OWASP failure that unguided AI code introduces constantly. - Binary pass/fail. Each scenario compiles directly into a failing Vitest, Jest, or Pytest test. The agent's success condition becomes deterministic: green tests, or not done.
From Coder to Technical Director
The role shift we described in the first post of this series - engineer as technical director rather than coder - only lands if the director is holding a real script. You cannot direct what you have not defined.
Success in 2026 will not be measured by how many lines of code your team vibes into existence. It will be measured by the quality of the constraints you hand to the agents doing the work. High-fidelity specs are where that measurement starts - and where the distinction between teams that ship production-ready AI-assisted software and teams that ship reviewable drafts actually gets made.
When your specifications are as rigorous as your source code, your agents stop generating-and-praying and start shipping production-ready software. The bottleneck moves from typing speed to thinking clarity - which is where it should have been all along.
Ready to evolve your team's specifications into production-grade agent instructions? Let's talk about rolling out Spec-Driven Development across your engineering organization.
Find Kipanga useful? Add us as a preferred source and Google will surface more of our work in your results.

25+ years in technology innovation. Founder and former CTO of MyFleet, a leading telematics platform. Technical Lead for GenAI at University of Newcastle. Expert in AI, Machine Learning, IoT, and Agile development.
View profile
Ready to scale your operations?
Let's discuss how Kipanga can architect the systems that power your next phase of growth.
Start the Discovery